
2024. 11. 26. 20:15, note
Spark: Join optimization를 번역하였습니다.
조인(join) 연산은 테이블을 결합하는 과정으로 비용이 많이 들며, 데이터 셔플(shuffle)과 성능 병목현상을 초래할 수 있습니다.
조인을 수행하기 전에
데이터 제한(Limit Data)
조인 작업 전에 DataFrame에서 불필요한 행(Row)과 열(Column)을 필터링하여 데이터를 줄이세요.
- 데이터 셔플 중 전송량 감소
- Executor 처리 시간 단축
join_default = product.join(catalog, ['product_id'])
# 행 제한(Predicate Pushdown): 특정 조건에 맞는 행만 필터링
# 평점이 4 이상인 제품만 반환
product_4star = product.select('product_id', 'product_name')\
.filter(col('rating') > 3.9)
# 열 제한(Projection Pushdown): 필요한 열만 선택
# catalog 데이터셋에서 product_id와 category 열만 스캔
catalog_ = catalog.select('product_id', 'category')
join_optimized = product_4star.join(catalog_, ['product_id'])Catalyst Optimizer 활용
고수준 Spark API 사용: DataFrame, Dataset, SparkSQL을 활용하세요. Dynamic Frame이나 RDD를 사용하는 경우 Catalyst Optimizer의 최적화를 적용할 수 없습니다.
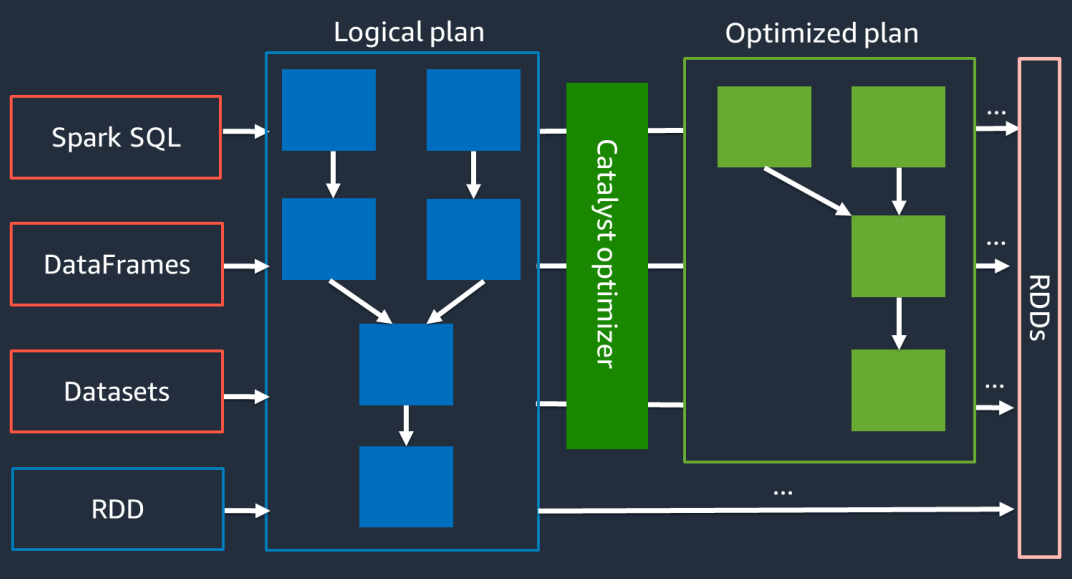
적응형 쿼리 실행(AQE, Adaptive Query Execution): Catalyst Optimizer는 실행 중인 Spark 작업에서 런타임 통계를 활용하여 쿼리를 최적화합니다.
Broadcast Hash Join
Broadcast Hash Join은 데이터 셔플(shuffling)이 필요 없으며, 작은 테이블과 큰 테이블을 조인할 때만 적용할 수 있습니다.
작은 테이블이 단일 Spark 실행기(executor)의 메모리에 적합한 경우 Broadcast Hash Join을 사용하는 것을 고려하세요. 이 방식은 작은 RDD를 각 워커 노드로 전달한 후, 큰 RDD의 각 파티션과 맵-사이드 결합(map-side combining)을 수행합니다.
from pySpark.sql.functions import broadcast
# DataFrame
joined = large_df.join(broadcast(smaller_df), right_df[key] == left_df[key], how='inner')
# SparkSQL
SELECT /*+ BROADCAST(t1) */
FROM t1 INNER JOIN t2 ON t1.key = t2.key;Shuffle Join
- 셔플 해시 조인(Shuffle Hash Join): Shuffle Hash Join은 정렬 없이 두 개의 데이터 프레임을 조인합니다. Spark 실행기(executor)의 메모리에 저장할 수 있는 두 개의 작은 테이블을 조인할 때 적합합니다.
- 정렬-병합 조인(Sort-Merge Join): Sort-Merge Join은 다음 과정을 거쳐 조인을 수행합니다: 데이터 프레임을 셔플(Shuffle) → 데이터를 정렬(Sort) → 조인 수행. 이 방식은 대규모 테이블 조인에 적합하지만, 메모리 부족(OOM) 문제와 성능 저하를 초래할 수 있습니다. 이런 경우, 버킷화(Bucketing)를 통해 조인의 효율성을 높일 수 있습니다.Bucketing버킷화는 조인 키를 기준으로 데이터를 미리 셔플하고 정렬한 후 중간 테이블에 저장합니다. 이를 통해 대규모 테이블 조인 시 셔플과 정렬 비용을 줄일 수 있습니다.
조인 전 재파티셔닝(Repartition before Join)두 RDD가 동일한 키와 동일한 파티셔닝 코드로 파티셔닝되어 있다면, 조인해야 할 RDD 레코드가 동일한 워커 노드에 위치할 가능성이 높아집니다. 이는 셔플 활동과 데이터 불균형(skewness)을 줄여 성능을 향상시킬 수 있습니다.# 버킷화 테이블 생성 df.write.bucketBy(30, 'orderId').sortBy('orderDate').saveAsTable('bucketedOrder')return_ord = returns.repartition(N, 'product_id') order_rep = order.repartition(N, 'product_id') joined = return_ord.join(order_rep, 'product_id')
'note' 카테고리의 다른 글
| 예제로 살펴보는 AI를 위한 데이터 엔지니어링 (0) | 2024.11.30 |
|---|---|
| Kubernetes HPA (Horizontal Pod Autoscaler) 알아보기 (0) | 2024.11.27 |
| Kubernetes의 Probe 알아보기 (0) | 2024.11.25 |
| 도커 멀티스테이징 (0) | 2024.11.24 |
| Apache Spark RDD(Resilient Distributed Dataset) (0) | 2024.11.22 |